Exploring the Cauchy distribution and electricity spot prices
For a while now I’ve been fascinated by a probability distribution known as the Cauchy distribution. I first learnt about it through reading the books of Nicholas Nassim Taleb (The Black Swan, Antifragile) and later Benoit Mandelbrot (The (Mis)behaviour of Markets). Both of whom discuss the distribution in the context of financial risk.
The reason the Cauchy distribution is so fascinating is because it does not have a defined mean or variance. Essentially, if you sample from a Cauchy distribution, no matter how many samples you have, calculating the mean or variance of this distribution will not converge to a single value, contravening the central limit theorem. The variance, in fact, will diverge and is infinite. This is in stark contrast to distributions like the Gaussian, for which a rule of thumb is that 30 observations would give you a good estimate of its true parameters. Furthermore, the Cauchy distribution is no mathematical curio, it occurs in the real world in applications such as physics and finance.
With this in mind, I’m going to explore the properties of the Cauchy distribution and look at how it can be applied to Australian electricity spot-prices using a model developed by Powell 1.
What is the Cauchy distribution?
As discussed above, the Cauchy distribution is a probability distribution with undefined mean and variance. The probability density function is defined as:
\[f(x|x_{0}, \gamma) = \frac{1}{\pi}\frac{\gamma}{(x - x_{0})^2 + \gamma^2}\]Where $x_{0}$ is the location parameter, giving the centre of the distribution, and $\gamma$ is the scale parameter which is effectively the variance. Interestingly, with $x_{0} = 0, \lambda = 1$, the Cauchy distribution is identical to the student’s t-distribution with one degree of freedom (i.e. for two observations). This distribution can also be realised as the ratio of two independent Standard Gaussian distributions.
Below I’ve sampled $10,000$ observations from a $Cauchy(x_{0} = 0,\lambda = 1)$ and a $Normal(\mu = 0,\sigma^{2} = 1)$ distribution. I’ve estimated and plotted the mean and standard deviation on a rolling basis. The plot shows how the estimates of scale and location vary significantly for the Cauchy distribution.
On the left, after some initail volatility, the Cauchy location estimate appears to approach the true location (0), but suddenly jumps at around $x=5,000$ and fails to return to 0. In contrast, the Normal distribution quickly reaches almost exactly 0 and stays there as more samples are accumulated. On the right, the result is even worse - the estimate of the Scale (i.e. variance) gets larger as more samples are accumulated, while the estimate for the normal sits nicely at 1 - the true value.
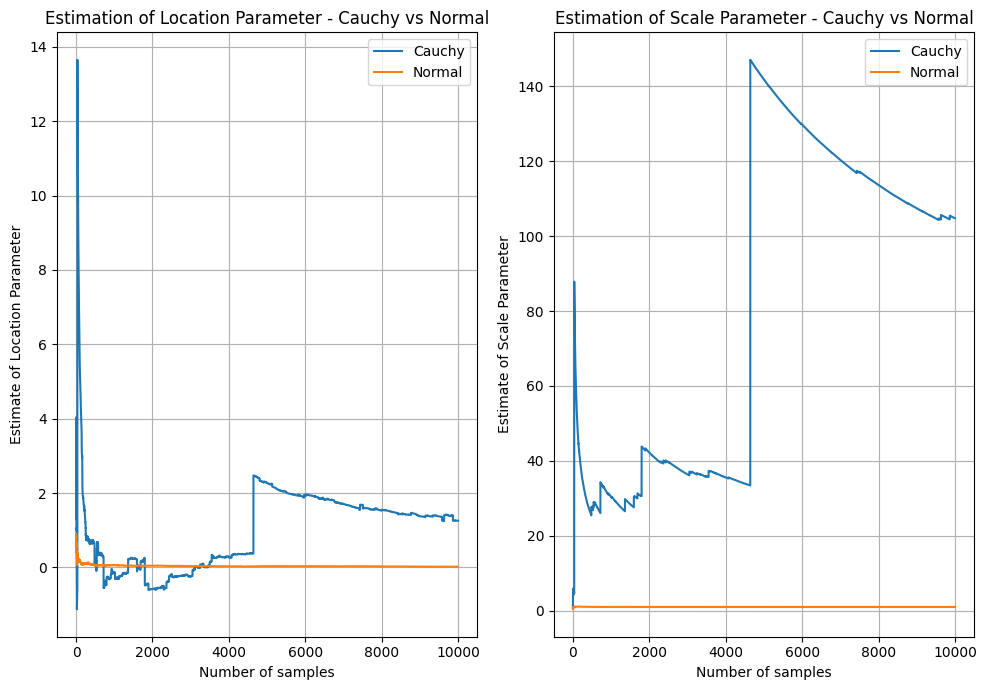
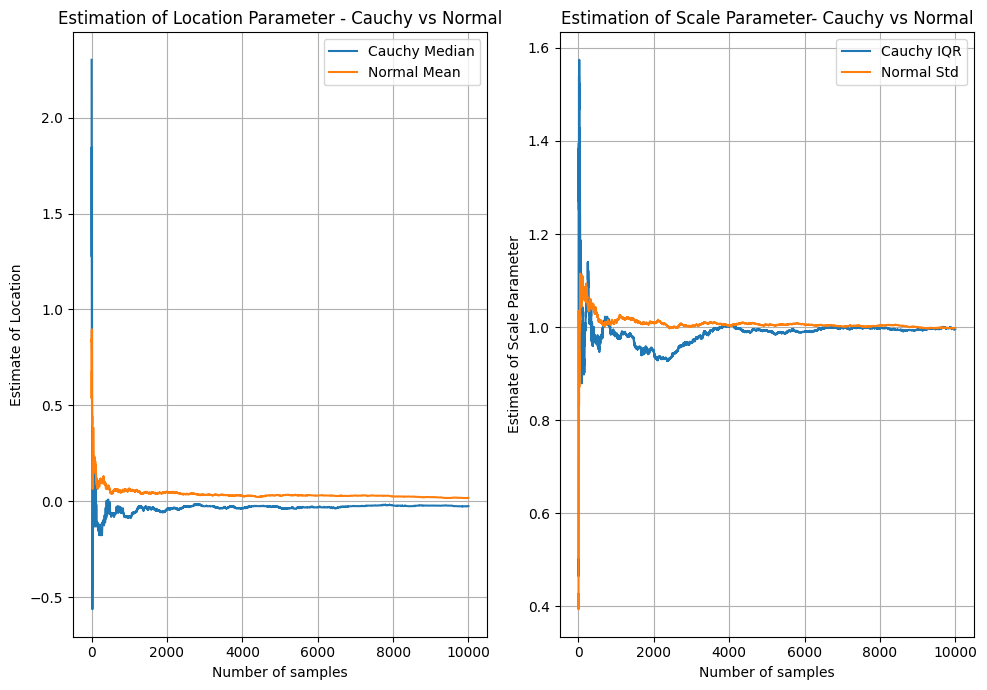
What this highlights, is that using the typical methods of estimating parameters like the location, that can work well for Gaussian, Exponential, Poisson and other distributions with finite mean/variance, does not work well for the Cauchy. This might come as a shock as the Maximum Likelihood Estimate (MLE) of the location parameters of these distributions is simply the arithmetic mean - probably the most widely used and understood statistic in existence! Naturally - there are a variety of ways of fitting the parameters of the Cauchy distribution. MLE is one way - noting that the arithmetic mean used above is not the MLE estimate of location for the Cauchy distribution. An even simpler way is to treat the location parameter as the median of the distribution and the scale as the inter-quartile range. Quantile estimates are less responsive to the extreme outliers that occur in the Cauchy distribution, hence they are more stable. The below plot compares these estimates for the same data and the same Gaussian mean/standard deviation estimates. You can see that both are much more stable and appear to reach the true value and remain stable.
The Cauchy Distribution and Electricity Spot Prices
Observing this strange behaviour made me curious - it is all well and good observing this behaviour in the above contrived setup, but what about in the real world? In a sample of data taken from the real world, could you really see this kind of non-convergent behaviour?
I found one such instance in a paper by Kim and Powell 1, where they analyse electricity prices in the US and find that the Cauchy distribution is a good fit for modelling the error term of a median-reverting model of hourly spot prices. I decided to get some Australian data and see if I could replicate the model and view the Cauchy distribution in the wild.
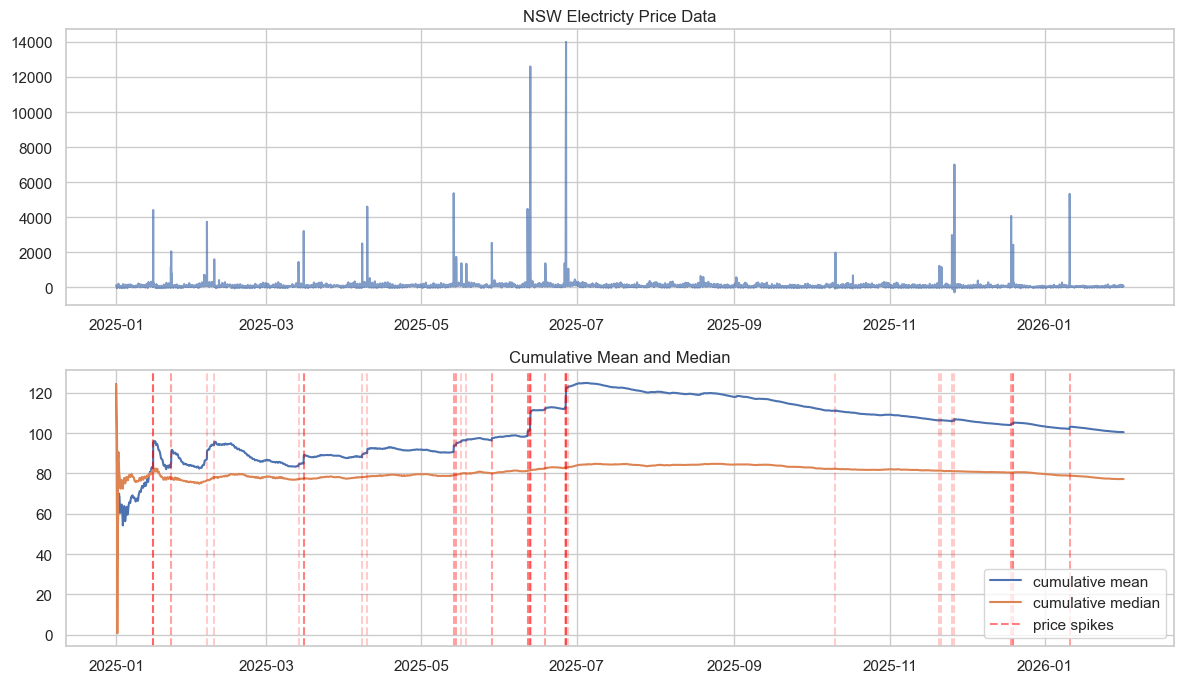
Using the OpenElectricity API 2 I was able to extract hourly electricty spot price data for NSW. Exactly the sort of data used in Kim and Powell’s paper. Plotting this price data below, we can see that the price behaviour is highly volatile with extreme spikes, and this affects the estimation of the mean. The mean estimate appears not to converge and be sensitive to sudden spikes, much like our simulated data above.
Over the course of the year, the trend electricity price may fluctuate due to seasonality, and this may mean we see a change in the mean - potentially resulting in non-convergence. But note, the types of changes we observe in the mean estimate are sudden and large, and they correlate with the extreme jumps in price (price spikes below are the 99.5th percentile price observations). This suggests that the reason for not converging is not due to seasonality or drift but rather the heavy tailed nature of the electricity prices. This is not to say there are no seasonal impacts on price - just that the instability in the mean estimate is not driven by them.
A Median Reversion Model of Electricity Prices
Powell and Kim develop a model of hourly electricity spot prices which assumes that prices revert towards the median 1. Their objective is to accurately model the tails of the price distribution to enable effective trading in the energy market. Their model follows the below equation:
\[p_{t+1} = p_{t} + (1 - \kappa) (p_{t} - \mu_{t}) \hat{\epsilon}_{t}\]Where:
- $\kappa = (1 - \bar{\mu}_{Y})$
- $\bar{\mu}_{Y} = \text{median}(Y_{t})$;
- $Y_{t}$ is the residual term;
- $\mu_{t}$ is a trailing monthly price median which accounts for seasonal variation in prices;
- $\hat{\epsilon}_{t}$ is the error estimate applied multiplicatively to the median reversion term.
Essentially, this model assumes that there is large uncertainty when the current price has deviated from the rolling monthly median. Naturally, the use of the median is driven by their analysis of the electricity prices where they observe a non-convergent mean.
It is worth looking at the residual $Y_{t}$ and error term $ \hat{\epsilon}_{t} $.
\[Y_{t} = \frac{(p_{t} - p_{t - 1})}{(\mu_{t - 1} - p_{t - 1})}\]Which is the ratio of the change in price to the deviation of price from the trailing median. Note that for the next step ahead prediction, $1 - \kappa = 1 - (1 - \mu_{Y}) = \mu_{Y}$ which implies that the strength of the median reversion is governed by the median value of the residual. That is, the median ratio of price changes to the difference between the price to the median monthly price is an estimate of how much pull there is back to the median price. If we have small price changes relative to that prices distance from the median, then there is only a small pull back to the median, in contrast if the changes are large, then there is a strong pull back to the centre.
The error term is given by:
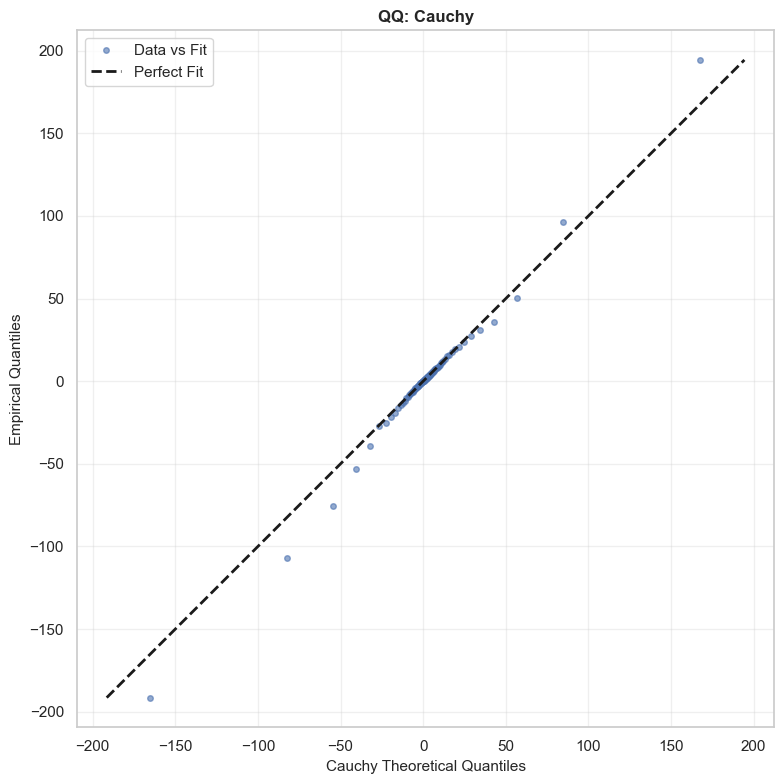
\[\hat{\epsilon}_{t} = \frac{Y_{t}}{\mu_{Y}}\]This is the term that Kim and Powell suggest is governed by a Cauchy distribution. In their paper, they estimate the tail parameter $\alpha$ and find that it is close to 1, implying infinite variance. 1 I’ve simply done a comparison here against a QQ-plot looking at the actual data vs a Cauchy distribution with $x_0 = 1$ and $\gamma \approx 5.23$. I’ve also estimated a Gaussian with $\mu \approx -3.5$ and $\sigma \approx 911$ (naively, without removing outliers), and another Gaussian using the same parameters as the Cauchy distribution - i.e. with Quantile Estimated Parameters (QEP). You can see clearly that the Cauchy distribution fits significantly better than either of the Gaussians,with each of these significantly over or under estimating the frequency for the tails. The Cauchy distribution is not perfect however, and appears to have more extreme tails than the actual data. Note, the analysis hereon is applied to a test set (Jan to mid Feb 2026) which was not used to fit the distributions or model. The training set comprised of NSW hourly spot price data for all of 2025.
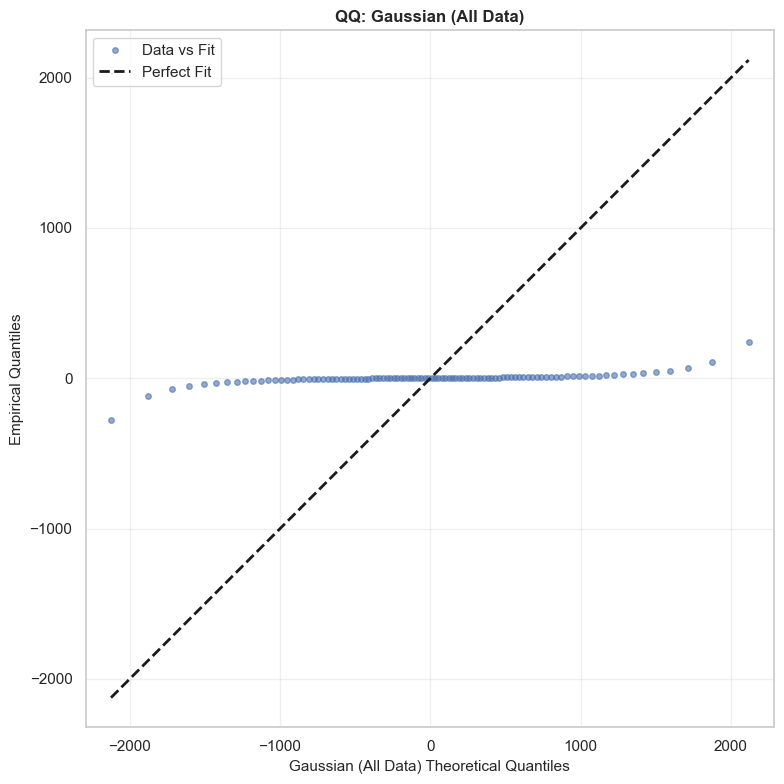
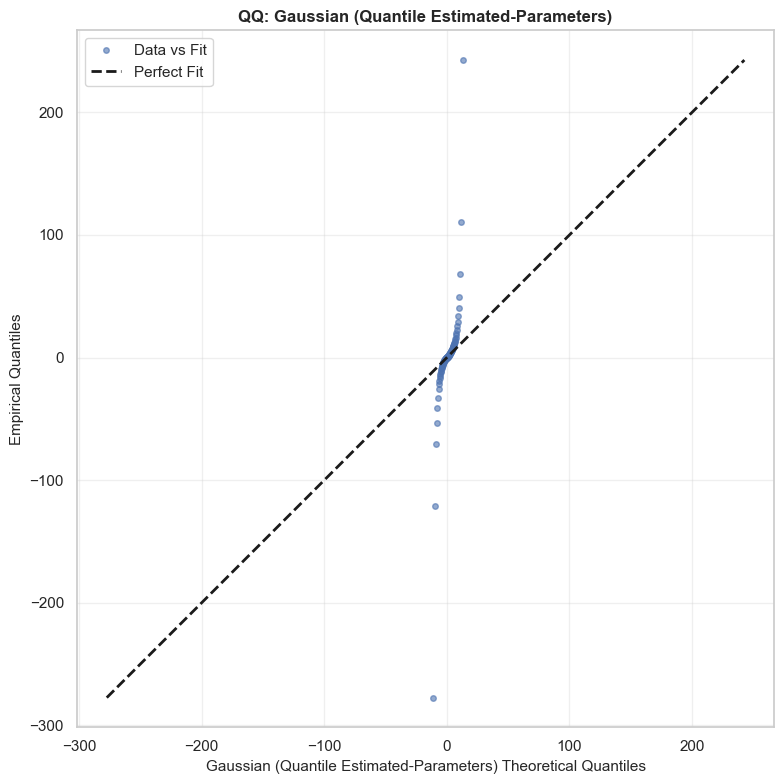
Quantile distributions of $Y$ show a good match as well (this is how Powell and Kim present their model fit before concluding the paper). You can see, the Cauchy quantiles match nicely with the actual distribution, while the naive Gaussian distribution are far from the mark around the tails. Essentially, while the variance is clearly large - the spread of prices between the 90th and 10th quantiles is over $2,000 for the naive estimate - the Gaussian distributions fail to account for the fact that there are massive rare events. They just assume that 80% of prices will be somewhere between +/- $1,000. This is not very specific and does not reflect the true distribution of prices.
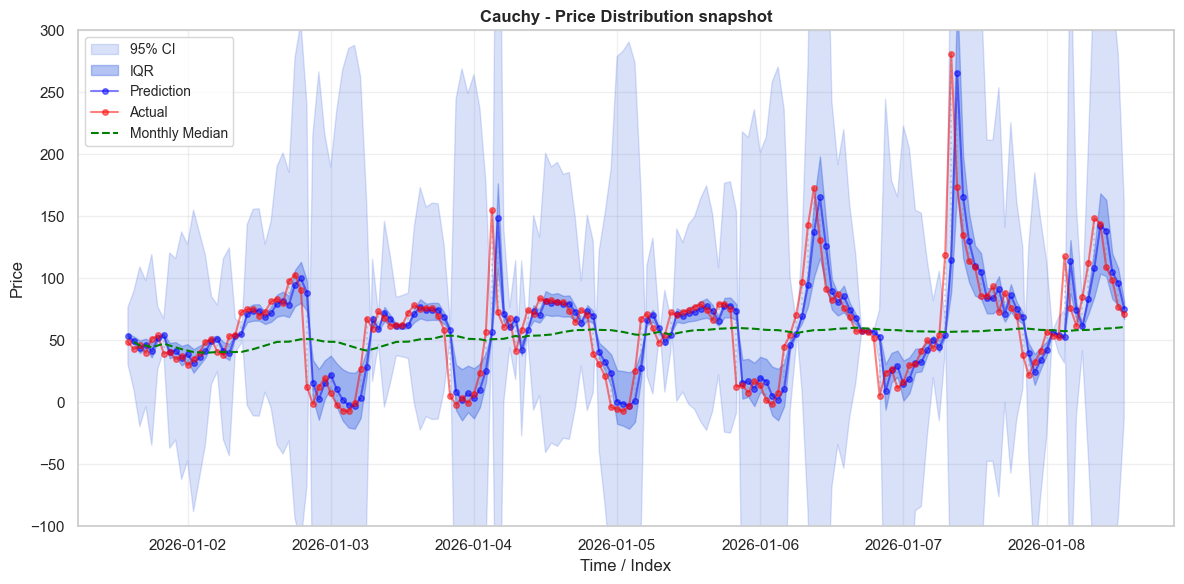
\[\small \begin{array}{|l|r|r|r||r|r|r|r|} \hline \text{Model} & \text{0.1} & \text{0.2} & \text{0.3} & \text{0.4} & \text{0.5} & \text{0.6} & \text{0.7} & \text{0.8} & \text{0.9} \\ \hline \text{Actual} & -15.998 & -6.245 & -2.562 & -0.503 & 1.016 & 2.711 & 4.807 & 8.089 & 17.546 \\ \text{Cauchy} & -15.108 & -6.204 & -2.802 & -0.701 & 1.000 & 2.701 & 4.802 & 8.204 & 17.108 \\ \text{Gaussian (QE-P)} & -5.707 & -3.405 & -1.745 & -0.326 & 1.000 & 2.326 & 3.745 & 5.405 & 7.707 \\ \text{Gaussian (All Data)} & -1171.762 & -770.723 & -481.545 & -234.454 & -3.503 & 227.447 & 474.539 & 763.716 & 1164.755 \\\hline \end{array}\]We can see this better when we look at actual prices. Below we plot the prices and predictions on the first week of test data. The distribution around the prices varies significantly between the error terms. As we saw in the quantile plot above, the all-data Gaussian distribution has unrealistically large tails. Almost every observation occurs well within the IQR of the Gaussian distribution - which should truly only have 50% of the observations. In contrast, the QEP Gaussian has tails that are two narrow. When prices shift up or down rapidly, prices will often sit ouside of the 95% CI entirely. The behaviour of the Cauchy distribution is much nicer - the IQR is appropriately narrow, and captures many observations. The 95% CI is much wider, and often captures prices when they grow rapidly.
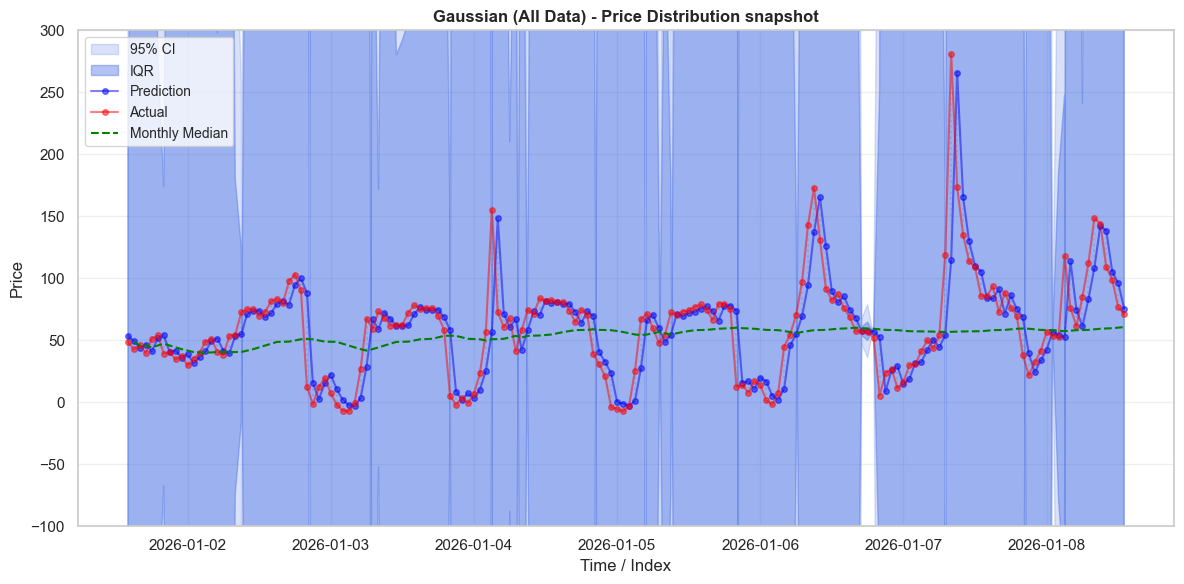
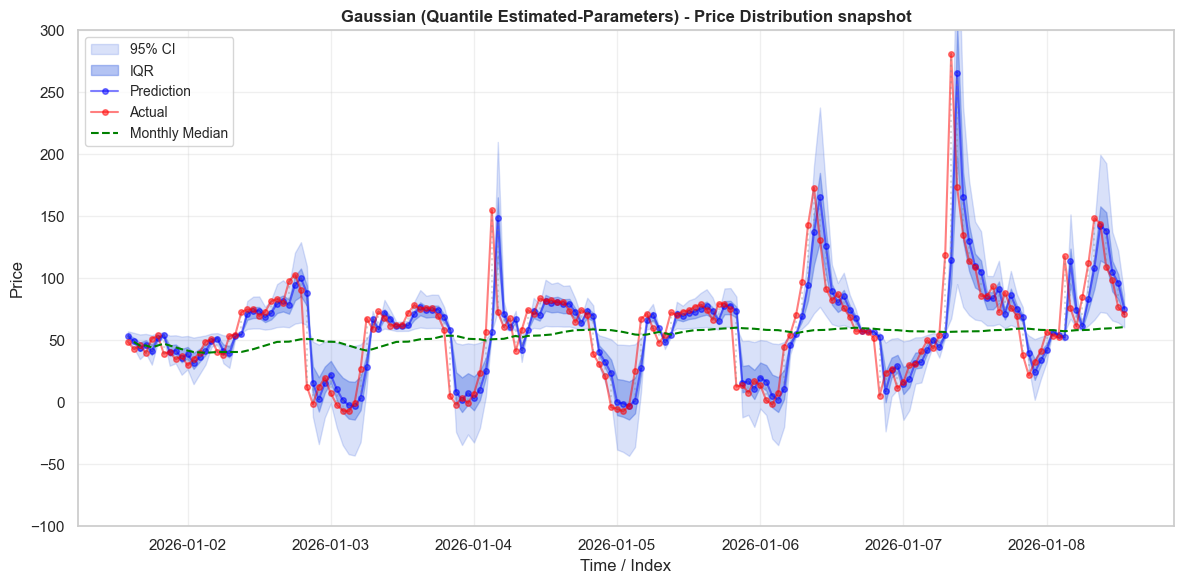
A third demonstration that the Cauchy distribution is the best of the three distributions considered is provided in the below table. The Cauchy distribution captures exactly 50% of price observations in its IQR, and just shy of 95% within the 95% CI. In contrast, the naive Gaussian distribution thinks that almost everything should fall within the IQR. It over states the probability of events occurring because it is highly responsive to the outliers in the data. While this distribution might assign every observed price a high probability, it doesn’t assign it an accurate probability, which is a problem if you want it to guide decision making. As anticipated, the QEP Gaussian under-estimates probabilities, with under 40% falling within its IQR and only 70% within its 95% CI.
\[\small \begin{array}{|l|c|c|c|c|} \hline \text{Distribution} & \text{Test in IQR} & \text{Train in IQR} & \text{Test in 95 CI} & \text{Train in 95 CI} \\ \hline \text{Cauchy} & 0.500 & 0.499 & 0.938 & 0.938 \\ \hline \text{Gaussian (QEP)} & 0.388 & 0.388 & 0.702 & 0.683 \\ \hline \text{Gaussian (All Data)} & 0.989 & 0.991 & 0.993 & 0.996 \\ \hline \end{array}\]Before finishing, I did want to analyse a price spike that occurs in the test data. Its interesting to see that despite its fatter tails, the Cauchy distribution can still miss outliers by potentially a large amount. It does do significantly better than the QEP Gaussian distribution which fails to include the whole trajectory leading up to the spike in its 95% CI. While the Cauchy distribution seems significantly better as a decision making guide, there is still the possibility of making very large mistakes.
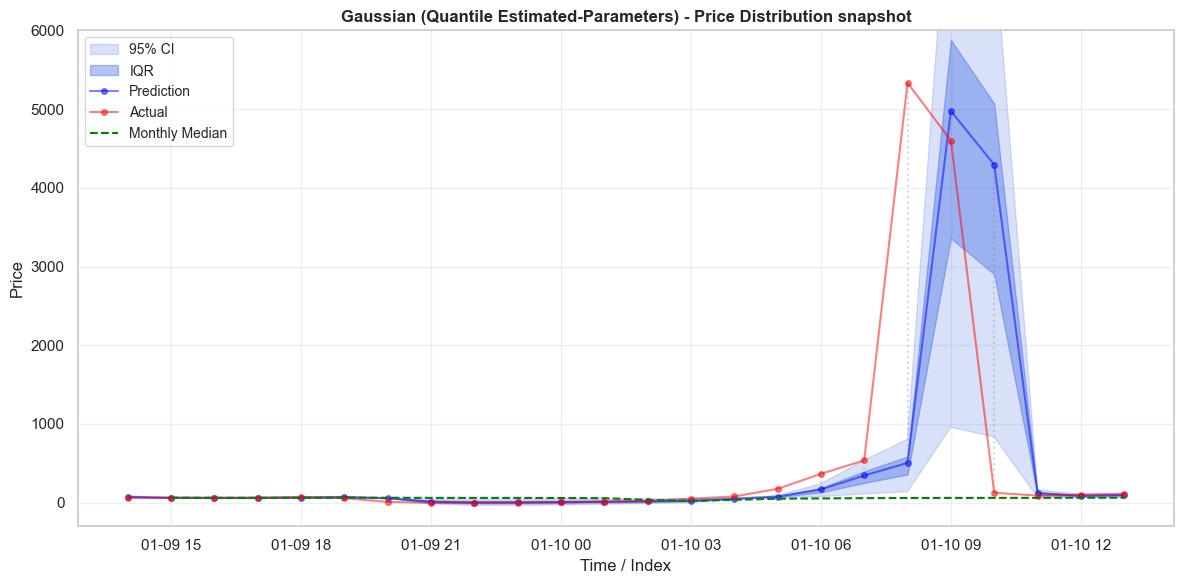
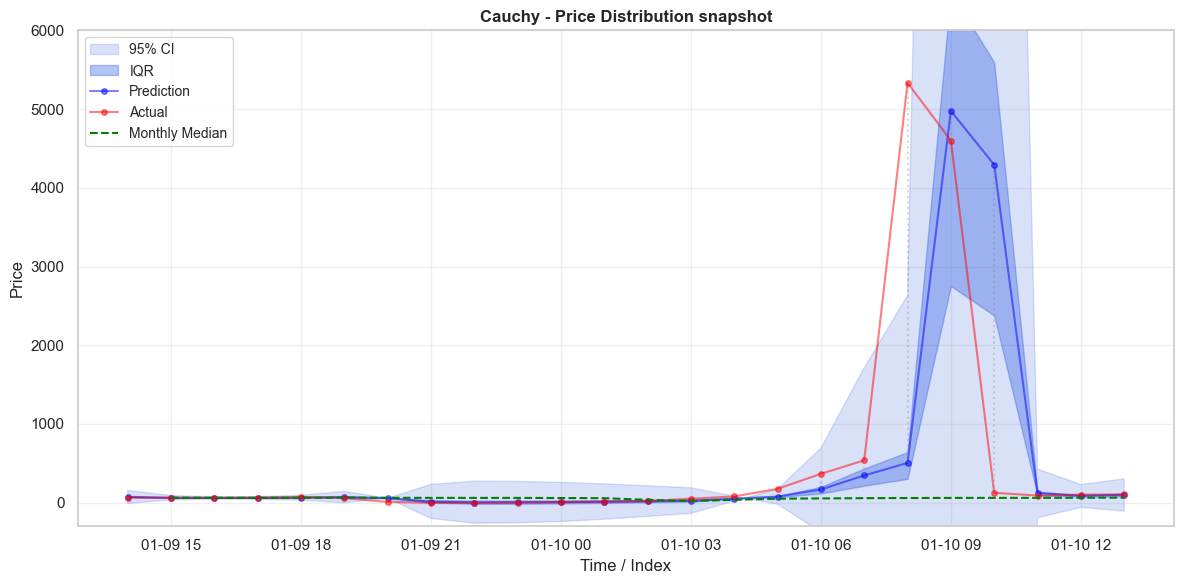
Conclusion
So we have seen that despite their unusual properties of not having undefined means and variances, the Cauchy distribution does occur in real world circumstances and can be applied in modelling them. One thing I’d be interested in learning more about is how to use a model such as the one implemented above. As it was designed for energy trading, I think it would be interesting to understand what strategies it could be used for. The first thing that comes to mind is for buying low / selling high with a probabilitistic forecast of future prices. But I do note - while the Cauchy model appears to have generally accurate predictions, it still seems capable of missing large price spikes. Furthermore, the model described above relies only on past prices - which likely have limited predictive power. Incorporating other features such as weather could be another interesting area to explore further.
References
-
Kim, J. H., & Powell, W. B. (2011). An hour-ahead prediction model for heavy-tailed spot prices. Energy Economics, 33(6), 1252-1266. https://doi.org/10.1016/j.eneco.2011.06.007 ↩ ↩2 ↩3 ↩4
-
Open Electricity. (2024). OpenElectricity API and Platform. The Superpower Institute. Available at: https://openelectricity.org.au (Accessed: 24 February 2025). ↩