Battery-based electricity trading with Claude
My Linkedin feed has recently been inundated recently with pretty wild commentary about how software developers and knowledge workers in general will be automated due to progress by generative AI products such as Claude Code. At the end of 2025 there seemed to be a prevailing view that AI was a bubble and there was no killer app that would make it economically worthwhile. Then, in early 2026, it felt like that view suddenly changed as Anthropic release Claude Code. To be perfectly honest, I’ve not been that excited about a future driven by LLMs, but they do seem to have growing capabilities and tools like code-assistants seem to open some exciting opportunities for people like myself, for whom writing code is a means to an end, rather than an end in itself.
Consequently, I bought a Claude subscription to better understand how the tool works and see if the hype is warrented. As a use case, I thought I would extend my previous exploration of electricity price modelling and use Claude code to build a battery trading simulation which applied the median reversion model from my previous article.
Electricity Trading Problem Statement
My previous post looked at the distribution of hourly electricity prices and how they could be modelled using a Cauchy distribution. While this was an interesting way to explore the application of the Cauchy distribution, I was interested to explore what practical uses this may have. Kim and Powell 1 proposed that this type of forecasting model could be used to guide electricity trading. I based the design of my simulation on a case study from Warren Powell’s “Sequential Decision Analytics and Modeling” 2.
We assume we have a battery of fixed capacity and that our buy/sell decisions do not affect the overall market. At each time period we observe a state variable $S_t = (p_t, \text{SoC}_t)$ where SoC is the battery’s state of charge. The decision we make is the portion of SoC we want to sell, or how much power we want to buy from the grid. We represent this as a variable $X_t \in [-1, 1]$, where negative values represent purchasing. Our objective is to maximise the cumulative revenue we make over the simulation period, given by $R = \sum^T_{t=1} p_t X_t$.
In addition to testing Claude Code, I wanted to explore what sort of trading strategies I could design - admittedly not knowing much about them and not researching very much at all. I also wanted to test out whether knowledge of the uncertainty could help decision making. This is, if we incorporate the median reversion model built around the Cauchy distribution, could the knowledge of the large uncertainty help decisions to buy or sell?
Building the Simulation with Claude
Using the actual electricity data from NSW I used previously, this simulation is pretty easy to create. As such, I thought it would be a good test case for using Claude Code. I arbitrarily chose the battery specs based on the New England 1 battery in NSW, giving it a capacity of 200MwH and charge / discharge rate of 100Mw.
Planning and Design
I had previously used some coding assistants before starting this, having briefly played with CoPilot, and done much copy-pasting from ChatGPT/Gemini. My main takeaway was that using LLMs to assist to code was great if you had a clear idea of what to build and how you wanted to structure it. Full vibe codeing - where one gives a high-level objective and gets the LLM to build everything - often started alright then quickly devolved into nonsense, tech-debt and a lot more work than was originally intended.
Consequently, I did some pen and paper thinking around what the system would look like, and engaged Claude Code’s planning mode. I asked Claude to develop certain classes with certain methods and purposes. This was based on my idea of how the system should work. For example, I wanted a simulation class and a policy class. The simulation was a Gymnasium like environment, while the policy class would handle decision making and parameter tuning. Claude did a good job, but there were often little embellishments which I didn’t like or didn’t request. These were often stylistic rather than deviations from objectives.
Code Overload
A key challenge I found was that Claude can generate so much code so quickly that it is hard to keep up. I would ask for several different classes and they would be built for me in minutes. While code generation is rapid, actually checking that you get what you ask for is a (more) time-consuming process than it used to be. When you write the code as you go you often check bits and pieces as you go. The greater familiarity you get by being hands on helps you review stuff that goes wrong. In contrast, getting everything written up front can be difficult to follow, it requires you to ingest large amounts of someone else’s code.
To be perfectly honest, I didn’t review and ingest the code each time I generated it. Often I would scan it, ask the LLM questions and get it to write tests. Sometimes I would pick up issues in my scan and would ask Claude to fix them. This worked, but I’d also suggest that it might not be enough if this were not a throw away exploratory project.
Structure helps
As mentioned above, based on my previous experiences with coding assistants, I found moving too fast made a mess. Being more targeted with your requests and being clear about your design helps. Once I had set up the classes and environments for the simulation I found it was easier to move faster. Through reviews and interactions I became familiar with Claude’s interpretation of my requests and this helped me plan out my next steps.
There was a point where I had several policy algorithms I wanted to implement - ranging from simple rules, Model-Predictive-Control (MPC) variants to Reinforcement Learning (RL) agents. Having developed a structure to build these policies I could simply tell Claude to develop a new policy and edit the learn method in such and such a way, and make sure the action method did blah. It became pretty rapid here as I was able to request that Claude make different policy variants. I’d also set up a notebook to run evaluations which helped me check the model behaviour.
I think a key thing I’ve learnt with coding assistants is that having examples to point to can greatly improve their output. In at least one case I developed a prototype class and asked Claude to mimic it. This was an alternative to me explaining in painstaking detail how I wanted a model to work. This is another form of structure that can be provided to help with code generation.
Unavoidable Vibing
Despite providing structure, there were still cases where Claude would embelish or fill in gaps in my requests. This could be good or bad. As an example of a good embellishment, I requested an oracle policy that used full knowledge of the price trajectory to select the optimal action. I thought (wrongly) that this would just involve summing the absolute values of the available prices, but such an approach wouldn’t take into account constraints on battery capacity. Claude automatically developed an approach that used linear programming to optimise the charge/discharge decisions. This approach was better than my original plan. But Claude didn’t ask or clarify any ambiguities in my request, which might have been a better flow. By asking or clarifying (as a person might) we may have identified a better option, or avoid implementing the wrong thing. Nonetheless, it still definitely achieved the outcome I wanted.
A less good embellishment was when I requested a threshold policy - one that sets thresholds for buying / selling electricity - that used a threshold based on the deviation between a monthly median price and actual price rather than the absolute price. Rather than following the structure of existing threshold policies, Claude developed a an approach that was fundamentally different. When I asked about the difference it told me that it was effectively the same - which wasn’t true. This kind of issue is frustrating as it is a tool just choosing not to do what it is being instructed.
Some embellishments were just hard to spot and it was not always clear whether they were dangerous or not. Late in the piece I found a few odd decisions which were not what I’d asked for which Claude had created. For example, it had decided to use different efficiency penalties for charging and discharging a battery. I’d wanted a flat value of $\eta$ applied to both charging and discharging decisions, but it decided to use $\frac{1}{\eta}$ for discharging. Perhaps there is some reason that you should do this for battery modelling, but it was different from what I’d asked for. It just goes to show checking and reviewing the work of coding agents is essential.
Drunk on Power
Another final reflection is that once things were easy to implement, I found that I was able to request all sorts of algorithms be built. This was cool, and I think reflected that I’d designed a reasonably good code structure. However, when I first came to write this post, I reflected on what I was actually comparing in terms of policies and it had strayed far from my original intentions. I had side-tracked myself into building Reinforcement Learning algorithms which didn’t really evaluate the impact of using probabilistic forecasts. Essentially the ease of building things meant that I hadn’t thought critically about what I wanted to build and had just built some random stuff. I needed to pull myself back and refocus. Claude and other code assistants cannot help you with that.
Summary of thoughts on Claude
So overall, Claude resulted in much faster code generation. It let me build things without tedious drugery. Algorithms which I have previously written from scratch were able to be generated in seconds. In fact, I could often specify the maths for an idea and Claude would write a good implementation with minimal adjustments.
Notably, this was an area which I had reasonably clear ideas about what I wanted to do - both conceptually and in terms of code structure. Without this things might be harder. As I noted, Claude would embellish or fill gaps that I did not realise were present. This could be useful and make me think further about what I wanted to do, but in terms of working efficiently and effectively it might have been better if it tried to clarify things.
Managing the quantity of generated code was a bit difficult. It was hard to switch between the high level conceptual thinking involved when planning with Claude, to the lower level analytical thinking required to review or write code. Often I found myself nodding along and just letting it do what it wanted. There was only one occasion where I went and wrote some actual code, but to get in this headspace I actually needed to take a break and come back.
I’d also note that writing code with Claude (or another AI assistant) is a bit of its own skill. There are a range of tricks - e.g. skills, multiple agents, Model Context Protocol - which I haven’t experimented with yet. But I’m pretty skeptical of vibe coding where people online claim to build an app with a single prompt or limited guidance. My experience is that when you want to build something specific, it takes more than a single prompt, and often a lot of thinking.
The Simulation - Algos and Results
So lets look at what I actually made. As noted, its a fairly simple electricity trading simulation using a battery. I wanted to try applying the median reversion model I implemented here to see how modelling prices with an accurate uncertainty estimate could help make decisions.
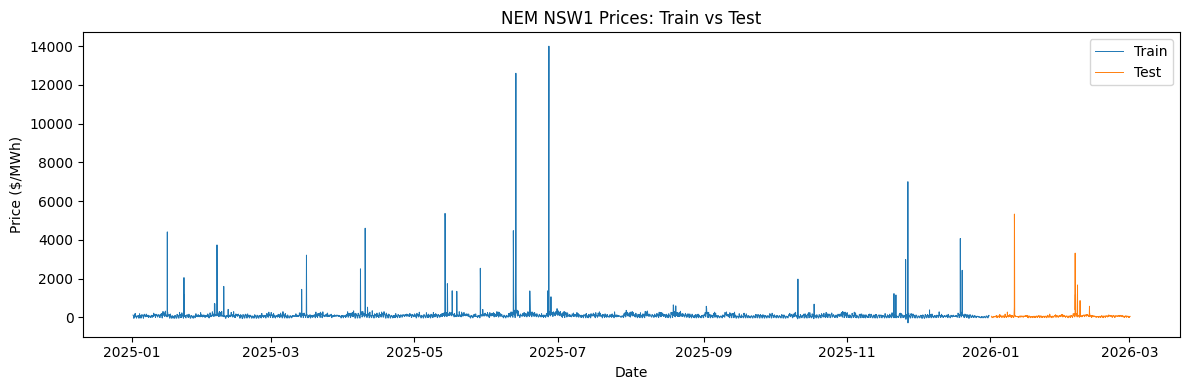
I trained (i.e. fit parameters) for each algorithm using 24 hour windows of data sampled from 2025 NSW hourly electricity spot prices. I then rolled out the first two months of 2026 as a test set, evaluating the cumulative revenue achieved by each algorithm.
Algorithm Descriptions
1. Deterministic Threshold
This algorithm is the simplest. Sell the maximum possible amount of electricity in each hour when the price is greater than some threshold, and buy the maximum possible amount of electricity in each hour when the price is less than some threshold. I fit the model doing a grid search over 2025 quantiles of electricity prices as the threshold candidates and simulating a sample of 24 hour windows.The quantile values that achieved the best cumulative revenue were evalutated.
Note that the threshold was chosen based on $p_{t-1}$, then the purchase decision corresponded to the $p_{t}$. This was based on the assumption that you didn’t know what the actual price was at the time of the decision. I applied this assumption to all algorithms.
2. Continuous Probability Threshold
This model uses the median reversion model to model the price distribution in the future. We sell the share of the maximum hourly amount given by $P(\hat{p}_{t} < \text{buy_threshold}) - P(\hat{p}_{t} > \text{sell_threshold})$. I like this approach because it chooses the amount to buy or sell based on the uncertainty of the future price. For example, if the probability of each of the thresholds is equal, then you stay put. But if the probability that the price will be below your buy threshold is more likely than the probability that the price will be above your selling threshold, you buy quite a lot.
3. Median Threshold
This algorithm was an instance where Claude didn’t do exactly what I asked it to do. It was a bit sneaky in that I asked it to review the algorithm design for consistency with other approaches, and it came back and advised me that it was. At first I acquiesced to its advice, but after later asking it to create a similar but slightly different algorithm it used the approach I originally suggested, I reflected that I’d been hoodwinked! The algorithm I wanted and have implemented now is that the battery sells power when the price’s deviation from the median is greater than a certain threshold, and buys when it is lower. It is similar to the price threshold versions above, except using deviation from median instead of absolute price.
4. Probabilistic Median Threshold
This is analagous to the “Continuous Probability Threshold” but using the deviation of price from median instead of absolute price. The proportion (of total battery capacity) of power sold is equal to $P(\hat{p}_{t} - \text{median}{t} < \text{buy_threshold}) - P(\hat{p}_{t} - \text{median}{t} > \text{sell_threshold})$, where the thresholds are set as deviations rather than prices.
5. Model Predictive Path Integral (MPPI)
This approach is a Model Predictive Control approach which uses the median reversion model as a dynamics model. The MPPI algorithm (see this post for a description) is used to sample actions over a 12 hour window. We use the median reversion model to simulate price dynamics forward in time as required for the MPPI algorithm.
6. and 7. Linear Programming methods
Claude developed the Linear Programming approach as an oracle model. My initial request was for an oracle baseline that had perfect information about prices. The intent was to benchmark other algorithms. I didn’t concieve of the Linear Programming approach, but it makes a lot of sense because it factors in battery capacity constraints. My initial approach was just to sum the absolute value of prices. This approach was not sufficient because it didn’t consider SoC and how previous decisions might impact future ones.
Building on the Linear Programming approach, I suggested a similar approach that used the median forecast over the next 12 hours that was fed to the same linear program. This offered a non-oracle approach that could be used as a trading model as well.
I’ve used Claude to summarise the LP and provided a description of variables in the table below.
\[\begin{aligned} \max_{c, d} \quad & \sum_{t=1}^{T} p_{t+1} \,\Delta t \left(\eta\, d_t - c_t\right) \\[6pt] \text{s.t.} \quad & -\eta\,\Delta t \sum_{s=1}^{t} (c_s - d_s) \leq E_0 - E_{\min}, && t = 1,\ldots,T \\ & \eta\,\Delta t \sum_{s=1}^{t} (c_s - d_s) \leq E_{\max} - E_0, && t = 1,\ldots,T \\ & 0 \leq c_t \leq \bar{c}, \quad 0 \leq d_t \leq \bar{d}, && t = 1,\ldots,T \end{aligned}\]| Symbol | Definition |
|---|---|
| $c_t,\, d_t$ | Commanded charge and discharge power (MW). Both non-negative; net action is $u_t = c_t - d_t$. |
| $\Delta t$ | Interval duration (hours). |
| $\eta \in (0,1)$ | One-way efficiency applied symmetrically: both charging and discharging transfer $\eta$ times the commanded power. Energy balance is $E_t = E_0 + \eta\,\Delta t\sum_{s=1}^{t}(c_s - d_s)$. |
| $E_0$ | Battery energy at the start of the horizon (MWh). |
| $E_{\min},\, E_{\max}$ | Energy bounds: $E_{\min} = 0$, $E_{\max} = C$ (battery capacity in MWh). The two inequality pairs enforce these at every prefix $t$. |
| $\bar{c},\, \bar{d}$ | Maximum charge and discharge rates (MW). |
Simulation Results
The simulation results are shown below. The left plot shows the trajectory of revenue, with the oracle (upper-bound benchmark) shown in gray. The right shows the total revenue achieved over the period. Below these plots is the distribution of the train and test prices, showing the typical volatile distribution of hourly electricty prices.
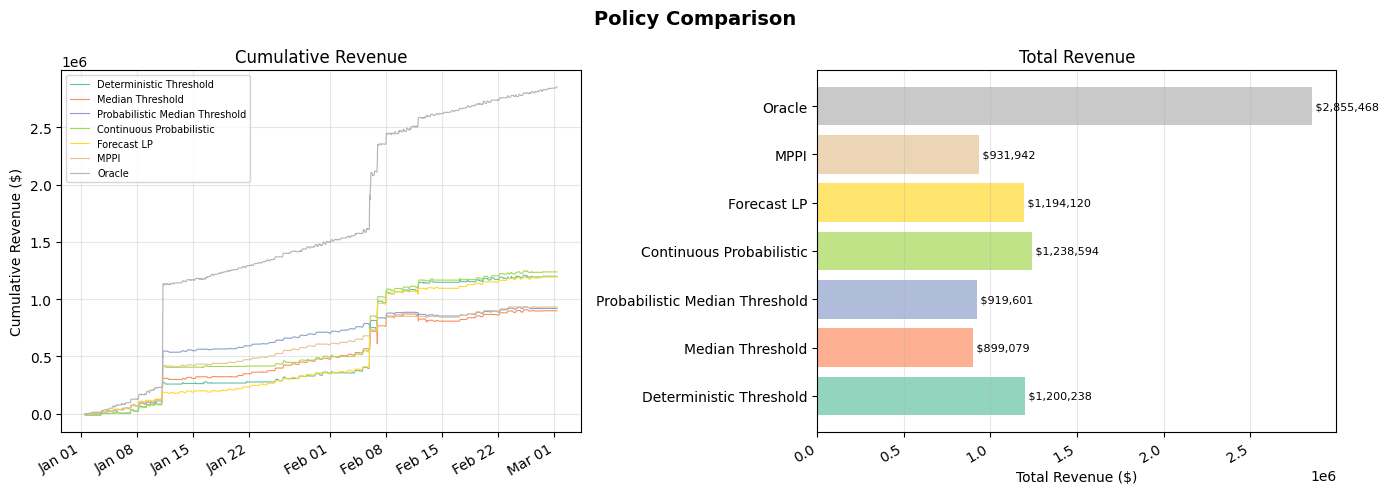
My key takeaway from these results is that taking advantage of the spikes is decisive for maximising cumulative revenue. Cumulative revenue growth between price spikes is comparatively slow. For example, the Probabilistic Median Threshold algorithm is leading after the first spike occurring around Jan 10, but then falls to second last after failing to take advantage of the second volatile period in mid-Feb. In contrast, while the Forecast LP and Deterministic Thresholds performed poorly in the first spike, they later pip the Probabilistic Median Threshold algorithm by a decent margin.
In contrast, the impact of incorporating probabilistic information does not seem to have a major impact. While the probabilistic counter-parts to deterministic approaches performed slightly better, the difference was relatively small, and may be just due to this dataset. MPPI performed worse than the forecast LP on average. Note that the MPPI contains randomness in its sampling process, so we ran it 10 times. It only beat the forecast LP on two occassions.
Conclusion
In summary, we haven’t conclusively determined if including probabilistic estimates of prices can help improve buy/sell decisions for energy trading. While we saw some successes, overall the improvement was small, and may be due to chance. What does seem to be important is the ability to identify price spikes before they can occur. Ensuring you can sell during these periods can drastically increase your cumulative revenue. Small losses or gains accrued at other times seem relatively inconsequential.
It is worth noting, however, that the analysis here is a bit slap-dash. The Australian electricity market doesn’t trade in 1-hour intervals (as far as I am aware), but rather 5-minute ones. Further, I haven’t done a deep analysis of the results here, or really explored what trading strategies are actually used. Rather, my analysis here has been a vehicle for me to explore Claude Code and how to use it.
On that front, its been an interesting introduction into the challenges and successes of agentic coding. My key takeaway on that front is that coding assistants are really amazing. They can rapidly develop well structured code. You can suddenly remove tedious repetitive writing of plots, algorithms or functions and avoid trawling through tedious or poorly maintained documentation. They can even run code, verify it works and respond to errors.
On the other hand, they can also embellish your requests with things you didn’t ask for or create something different from what you asked for. If you’re not clear they may fill the gaps in - for good or ill. Finally, building things rapidly comes with challenges. You still need to verify what they create, and when they create a lot of stuff rapidly, that creates a lot of work for you, rapidly. It also doesn’t know if the stuff you ask it to build is the right stuff to build. So whilst it might be easy to ask it to build one more algorithm, it doesn’t consider whether that is the right algorithm to build.
So whilst I think Claude code and other agentic assistants do add a lot of value and can make building things much easier, I also think that:
- They take some skill to use well, but these skills might be different from what skills are currently required to code well
- The productivity improvements may not be as large as they initially appear. New work is created to plan and review created code. Ensuring you’re system does what you want it to is even more important as silent bugs can easily be introduced and hidden during automatic code generation.
References
-
Kim, J. H., & Powell, W. B. (2011). An hour-ahead prediction model for heavy-tailed spot prices. Energy Economics, 33(6), 1252-1266. https://doi.org/10.1016/j.eneco.2011.06.007 ↩
-
Powell, W. B. (2026). Sequential Decision Analytics and Modeling (2nd ed.). Warren B. Powell. https://tinyurl.com/BridgingDecisionProblems/ ↩